
機械学習は、 人工知能(AI), 明示的なプログラミングなしにシステムがデータから学習し、時間の経過とともに改善できるようにすることで、産業に変革をもたらしています。 ガートナー, AIの世界市場は、その重要性の高まりと普及の広がりを反映して、2025年までに1兆5千億1900億に達すると予想されています。 マッキンゼー・グローバル・インスティテュート AIは2030年までに約1兆5千億1300億ユーロの経済効果をもたらし、世界のGDPを年間約1.21兆4千億ユーロ押し上げると予測されています。これらの統計は、ヘルスケアや金融からテクノロジーや小売業に至るまで、機械学習が様々な分野に大きな影響を与えていることを浮き彫りにしています。.
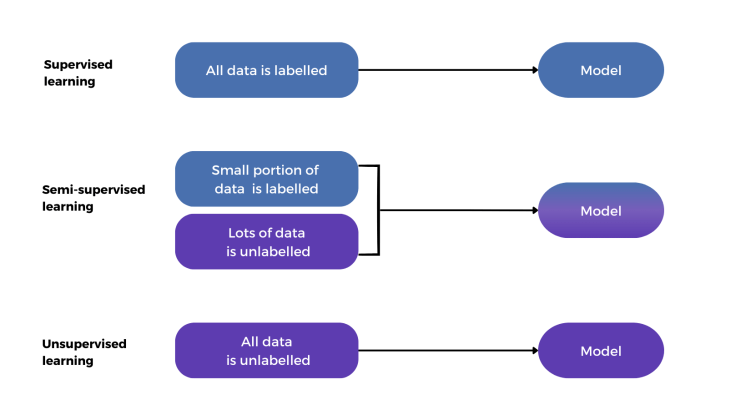
の領域では 機械学習, 入力と出力が明確に定義されているラベル付きデータは、モデルの学習において重要な役割を果たします。しかし、ラベル付きデータの取得には多くの場合、時間とコストがかかります。そこで半教師あり学習が役立ちます。半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを用いてモデルを学習することで、教師あり学習と教師なし学習のギャップを埋めます。このアプローチは、コストを削減するだけでなく、利用可能な膨大なデータを活用することでモデルのパフォーマンスを向上させます。.
この記事では、半教師あり学習の概念を深く掘り下げ、その定義、そして教師あり学習や教師なし学習との違いを探ります。この記事を最後まで読めば、半教師あり学習がAIの未来をどのように形作っているのか、そして様々な業界でイノベーションを推進する可能性について、包括的に理解できるでしょう。.
半教師あり学習とは何ですか?
半教師あり学習(SSL)は、機械学習(ML)のアプローチの一つで、大量のデータがあり、その一部にのみラベル付けされている場合に特に有効です。SSLは、教師あり学習と教師なし学習の両方の側面を組み合わせたものです。SSLをより深く理解するために、まずはこれらの基礎的な手法を見てみましょう。.
教師あり学習
教師あり学習 ラベル付きデータを用いてモデルをトレーニングする手法です。つまり、各データポイントは出力ラベルとペアになっています。この手法は、ラベル付きデータによって提供される正解の例からモデルを学習するため、「教師あり」と呼ばれます。.
例えば、画像内の果物の種類を分類するシステムを構築するとします。各画像に「リンゴ」や「バナナ」など、果物の正しい名前がラベル付けされた画像データセットが必要になります。システムは、画像内の特徴(色、形状、質感など)を正しいラベルにマッピングすることを学習します。このアプローチは効果的ですが、特に医療画像解析のような複雑なタスクでは、特定の状態を識別するために専門家によるラベル付けが必要となるため、時間とコストがかかる可能性があります。.
教師なし学習
対照的に、, 教師なし学習 ラベル付けされたデータに依存しません。代わりに、データを分析して隠れたパターンや固有の構造を見つけ出します。教師なし学習の一般的なタスクはクラスタリングで、アルゴリズムは類似したデータポイントをその特徴に基づいてグループ化します。.
例えば、ある製品に対する顧客レビューのコレクションがあるとします。教師なし学習を用いることで、これらのレビューを、使用されている単語やフレーズに基づいて、肯定的、否定的、中立的といった感情の異なるカテゴリーにクラスタリングすることができます。教師なし学習の課題は、最適なクラスタ数を決定するために多くの試行錯誤が必要になることが多く、結果として得られるクラスタの解釈が容易ではない場合があることです。.
半教師あり学習
半教師あり学習は、教師あり学習と教師なし学習の両方の長所を組み合わせたものです。まず、小規模なラベル付きデータセットでモデルを学習し、次にこのモデルをより大きなラベルなしデータセットに適用します。この手法では、ラベル付きデータを活用して学習プロセスを導きながら、膨大な量のラベルなしデータを活用してモデルのパフォーマンスを向上させます。.
例えば、メールのスパム検出システムを学習させる場合を考えてみましょう。まずは、「スパム」または「非スパム」と明確にラベル付けされた少数のメールから始めることができます。このラベル付けされたデータでモデルを学習させた後、モデルはラベル付けされていない大量のメールを分析し、ラベル付けされたサンプルで特定したパターンに基づいてメールを正確に分類することを学習します。このアプローチにより、数千ものデータポイントに手動でラベル付けする必要がなく、堅牢な予測モデルを構築できるため、時間とリソースの両方を節約できます。.
半教師あり学習はどのように機能しますか?
教師あり学習には大量のラベル付きデータが必要であり、教師なし学習には多くの実験と解釈が必要であることは既に述べました。半教師あり学習は、ラベル付きデータのサブセットでモデルを学習させ、それをより大きなラベルなしデータセットに適用することで、必要な労力を大幅に削減するという中間的なアプローチを提供します。しかし、このプロセスは具体的にどのように機能するのでしょうか?
半教師あり学習には、自己学習、共学習、グラフベースラベル伝播という3つの主要なバリエーションがあります。それぞれについて詳しく見ていきましょう。.
自己トレーニング
自己学習は半教師あり学習の最もシンプルな形式です。その仕組みは以下のとおりです。
- 小さなラベル付きデータセットから始めて、それを使用して教師あり学習モデルをトレーニングします。.
- このトレーニング済みモデルをラベルなしデータに適用して、疑似ラベル (機械生成ラベル) を生成します。.
- ラベル付きデータと疑似ラベル付きデータを組み合わせて新しいデータセットを作成します。.
- この結合されたデータセットで新しいモデルをトレーニングします。.
例えば、様々な果物のラベル付き画像が数枚とラベルなし画像が多数ある場合、まずラベル付き画像でモデルをトレーニングします。その後、このモデルはラベルなし画像のラベルを予測し、疑似ラベルを含む大規模なデータセットを作成し、モデルをさらに改良することができます。.
共同トレーニング
共学習では、同じデータセットで異なる特徴量(ビュー)を用いて2つのモデルを学習します。手順は以下のとおりです。
- ラベル付けされたデータからの異なる特徴セットで 2 つのモデルをトレーニングします。.
- 各モデルを使用して、ラベルのないデータの疑似ラベルを生成します。.
- 1 つのモデルの予測が非常に信頼できる場合は、その疑似ラベルを使用して他のモデルの予測を更新します。.
例えば、テキスト分類タスクでは、あるモデルを単語の頻度で学習させ、別のモデルを品詞タグで学習させることができます。これらのモデルは、2人の学生が複雑なトピックの異なる側面を理解するのを互いに助け合うのと同様に、確信度の高い予測を交換し、互いの学習を促進します。.
グラフベースの半教師あり学習
グラフベースの手法では、グラフデータ構造を用いてラベルを伝播します。その仕組みは以下のとおりです。
- データをグラフとして表現します。グラフでは、ノードはデータ ポイント、エッジはそれらの間の類似性を表します。.
- グラフの構造を分析して、ラベル付きノードからラベルなしノードにラベルを広げます。.
様々な動物の画像があると想像してください。類似した画像を繋げたグラフを作成することで、グラフ内の接続性に基づいて、ラベル付き画像(「猫」や「犬」など)のラベルをラベルなし画像に伝播させることができます。ラベルなし画像が「犬」画像よりも「猫」画像との関連性が高い場合、その画像は「猫」とラベル付けされます。“
半教師あり学習の例
半教師あり学習は、ラベル付きデータとラベルなしデータの両方を効率的に活用できるため、様々な業界で広く利用されています。その応用例を示す明確な例をいくつかご紹介します。
音声認識
音声認識では膨大な量の音声データが利用可能ですが、書き起こし(ラベル付け)されているのはごく一部です。半教師あり学習では、まずラベル付けされた音声データを用いてモデルを学習させ、発話単語を認識します。次に、このモデルを用いて、ラベル付けされていない音声データに疑似ラベルを生成します。ラベル付けされたデータと疑似ラベル付けされたデータを組み合わせることで、モデルはさらに学習され、精度が向上します。このアプローチは、コストと時間のかかる手作業による書き起こしへの依存度を低減し、堅牢な音声認識システムの開発に役立ちます。.
医療画像
MRIスキャンやX線などの医用画像診断では、異常箇所のラベル付けに熟練した放射線科医の手が必要になることが多く、多くのリソースを消費する作業となっています。半教師あり学習では、ラベル付けされた医用画像(腫瘍を示す画像など)の少数のデータセットを用いて初期モデルを学習します。その後、このモデルをラベル付けされていない画像のより大きなデータセットに適用し、疑似ラベルを生成します。これらのデータセットを組み合わせることでモデルを改良し、より正確に異常を検出できるようになります。この手法は、診断ツールの開発を加速するだけでなく、医療従事者の負担を軽減します。.
不正行為検出
金融サービスにおいて不正取引の検知には、膨大な取引データを分析する必要がありますが、不正とラベル付けされる取引はごくわずかです。半教師あり学習アプローチでは、まずラベル付けされた取引でモデルをトレーニングします。次に、このモデルはラベル付けされていない取引に疑似ラベルを割り当てます。ラベル付けされたデータと疑似ラベル付けされたデータの両方でトレーニングされた改良されたモデルは、不正パターンをより正確に識別できます。これにより、金融機関はより効率的かつ高精度に不正を検知できるようになります。.
テキスト分類
ニュース記事や顧客レビューの分類といったテキスト分類タスクでは、テキストデータのごく一部にしかラベルが付けられない場合があります。半教師あり学習では、ラベル付きテキストデータを用いて初期モデルを学習させます。このモデルは、ラベル付けされていないテキストに対して疑似ラベルを生成し、より大規模なラベル付きデータセットを作成します。その後、この統合されたデータセットを用いてモデルを再学習することで、新しいテキストを正確に分類する能力が向上します。このアプローチは、感情分析やスパム検出などのアプリケーションに特に有用です。.
これらの例は、さまざまな分野での半教師あり学習の汎用性を示しており、大規模な手動ラベル付けの必要性を最小限に抑えながらモデルのパフォーマンスを向上させる可能性を強調しています。.
半教師あり学習はいつ使用すべきでしょうか?
半教師あり学習は、ラベル付きデータの取得に費用や時間がかかり、専門知識が必要となる一方で、大量のラベルなしデータが容易に入手できるシナリオにおいて特に効果的です。半教師あり学習が有利となる主な状況は以下のとおりです。
高いラベルコスト医療画像や法務文書分析などの分野では、ラベル付けには専門知識が必要であり、コストと時間がかかります。半教師あり学習は、少量のラベル付きデータを活用することで、これらのコストを大幅に削減できます。.
ラベルなしデータの豊富さソーシャルメディア上のユーザー生成コンテンツや金融サービスの取引記録など、ラベル付けされていないデータが大量にある場合、半教師あり学習ではこのデータを活用してモデルの精度とパフォーマンスを向上させることができます。.
データの不均衡: ラベル付きデータセット内で特定のクラスが十分に表現されていない場合、半教師あり学習は、ラベルなしデータを組み込むことで、これらのまれなクラスを認識するモデルの能力を向上させるのに役立ちます。.
ラピッドプロトタイピング: プロトタイプを迅速に開発するために、半教師あり学習では、完全にラベル付けされたデータセットを待たずに効率的なモデルトレーニングが可能になり、開発プロセスが加速されます。.
半教師あり学習は、ラベル付きデータとラベルなしデータを効果的に組み合わせることで、ラベル付きデータは限られているがラベルなしデータは豊富にある状況で堅牢なモデルを構築するための実用的なソリューションを提供します。.
結論
結論として、半教師あり学習はAIと機械学習の分野における極めて重要な進歩であり、教師あり学習と教師なし学習の間のギャップを埋めるものです。ラベル付きデータとラベルなしデータの両方を活用することで、半教師あり学習は効率性、費用対効果、そしてスケーラビリティにおいて大きなメリットをもたらします。特に、大量のラベル付きデータの取得が困難または非現実的なシナリオにおいて、AIモデルの精度と堅牢性を向上させることができます。.
産業界が膨大な量のデータを生み出し続ける中で、有意義な洞察を抽出し、イノベーションを推進する上で、半教師あり学習の役割はますます重要になっています。音声認識、医療診断、不正検出、テキスト分析など、あらゆる分野で、このアプローチは汎用性と有効性を発揮しています。今後、急速に進化する人工知能(AI)の分野で、データリソースを効果的に活用し、競争力を維持したい組織にとって、半教師あり学習をAI戦略に統合することは不可欠となるでしょう。.





{kind=link}